
Cracking the Large-Scale ML System Design Interview
You’ve got the coding skills. You know your algorithms. But then the interviewer drops a bombshell: “Design a recommendation system for Netflix.”

Suddenly, your mind is a blur of neural networks and loss functions. But here is the secret: ML System Design isn’t about the model; it’s about the plumbing. Big tech companies like Google, Twitter, and Meta don’t just want to know you can train a model—they want to know you can build a system that handles billions of requests without melting the servers.
Based on the gold-standard “Grokking the ML Interview” curriculum, here is your Standout Blueprint for acing the design round.
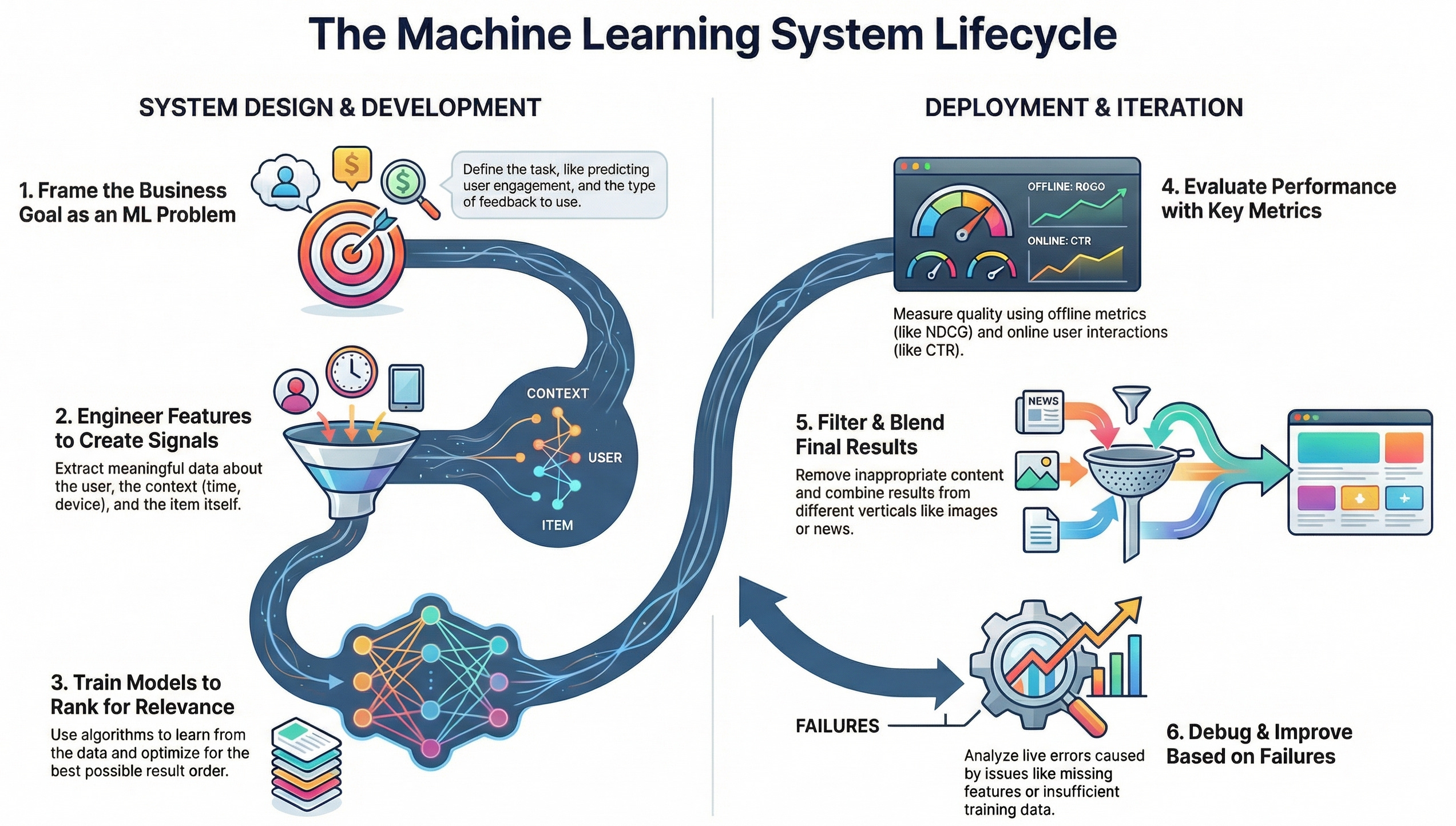
Phase 1: Don’t Be a Hero—Ask Questions First
The biggest mistake candidates make is jumping into the architecture. Stop. You need to define the boundaries.
The Clarification Checklist:
Scale: How many users? (Example: Twitter has 500M daily active users).
Latency: How fast must it be? (Example: Search results need to return in < 500ms).
Freshness: Does the model need to learn in real-time? (Example: Ad systems need “Online Learning” because ads are short-lived).
💡 Standout Pro-Tip: Use the “Twitter Scale” example. If 500M users fetch their feed 10x a day, your system runs 5 billion times per day. That changes how you pick your models!
Phase 2: The Magic of the “Funnel” (Architecture)
You cannot run a heavy Deep Learning model on every tweet or movie in existence. It’s too slow. Instead, we use a Layered Model Approach.
Stage 1: Candidate Generation (High Recall)
Goal: Sift through billions of items and find the top ~100,000 that might be relevant.
Method: Simple stuff. Inverted indexes (for search) or Collaborative Filtering (for Netflix).
Stage 2: Simple Ranking (The Trimmer)
Goal: Reduce 100,000 to the top ~500.
Model: Something fast, like Logistic Regression or a small MART (Multiple Additive Regression Trees).
Stage 3: Complex Ranking (High Precision)
Goal: Perfect the order of the top 500.
Model: This is where you bring out the big guns—Deep Neural Networks or LambdaRank.
Phase 3: Feature Engineering (The “Actor” Framework)
In the interview, don’t just list features. Group them by Actors. Let’s use the Netflix Recommendation example:
The User: Age, gender, location, and the “User-Actor Histogram” (what % of movies they watch starring Brad Pitt).
The Media: Genre, duration, release year, and “Content Tags” (e.g., “Visually striking nostalgic movie”).
The Context: Time of day (short clips on mobile during work vs. long movies on TV at night), or “Upcoming Holidays” (recommend The Grinch in December).
Cross Features: The interaction. “User-Genre Similarity”—how much does this user love Sci-Fi?
Phase 4: Dealing with “Dirty” Data
Real-world data is biased and messy. Interviewers love to see if you know how to fix it.
The Engagement Gap: In an Ad system, only ~2% of people click. If you train on all data, the model learns to predict “No Click” 100% of the time.
The Fix: Negative Downsampling. Throw away most of the “no-click” examples until you have a 50/50 split.
The Catch: Once you downsample, your probabilities are fake! You must Recalibrate the scores before they go to a live auction.
Phase 5: The Advanced Deep Dive (NLP & Vision)
Want to move from a “L4” to an “L6” Senior Engineer? Talk about these two concepts:
1. Contextual Embeddings (NLP)
Think about the name “Michael Jordan.” Is it the basketball player or the UC Berkeley professor?
Old way (Word2vec): Gives the same vector for both.
Standout way (BERT): Uses “Masked Language Modeling” to look at the words around the name to understand the context. BERT sees the whole sentence at once; ELMo looks left-to-right and right-to-left independently.
2. Data Expansion with GANs (Vision)
Designing a self-driving car? You probably have 50,000 photos of sunny California but only 10,000 of snowy Montreal.
The Fix: Use a cGAN (Conditional Generative Adversarial Network) to “translate” sunny images into snowy ones. This creates synthetic training data for those rare, dangerous edge cases.
Phase 6: The Final Test (A/B Testing)
You’ve built the model. Do you launch it? Not yet.
You must run an Online Experiment.
Split Traffic: Give 1% of users the new model (Variation) and 99% the old one (Control).
Measure: Check the P-value. If it’s
<0.05<0.05, the results are “statistically significant.”
Back-Testing: If your new model gives a 5% gain, run a back-test. Swap them. If the loss matches the previous gain, you’ve got a winner.
The Standout Summary (Cheat Sheet)
When the interviewer asks you to design an ML system, follow this flow:
Clarify scale and latency requirements.
Define Metrics (NDCG for ranking, IoU for vision).
Propose the Multi-stage Funnel (Retrieval -> Ranking).
Identify Features using the Actor Framework.
Explain how you will collect and balance data (Implicit feedback + Downsampling).
Suggest an A/B Test for the final rollout.
Want more deep dives?
If this helped you, share it with a friend who’s prepping for their next big interview. Let’s build better systems together!
Stay curious,
Teodora @ Standout Systems