
Day 20: Context Window Management - Feeding the Right Amount of Information to GPT
RAG for Healthcare | Day 20 of 35 | Free

You have spent three weeks learning to retrieve the right chunks. Today you learn how many to actually send.
A clinician asks a complex pharmacology question.
Your pipeline:
Hybrid search (Day 17) → reranking (Day 18) → metadata filtering (Day 19) retrieves 15 excellent chunks. Concatenated, they total 12,000 tokens. GPT-5.4 has a 1 Million token context window. Plenty of room, right?
Here is the problem: more context does not mean better answers.
Research consistently shows that LLMs pay the most attention to the beginning and end of the context, and tend to ignore information in the middle. This is the “Lost in the Middle” phenomenon. And it means that your 15 carefully retrieved chunks might perform worse than a well-ordered 5.
Lost in the Middle: The Problem
A landmark study by Liu et al. (Stanford, 2023) tested LLMs on a task where the answer was placed at different positions within the context. The finding: accuracy dropped 20–30% when the relevant information was in the middle of a long context, compared to when it was at the beginning or end.
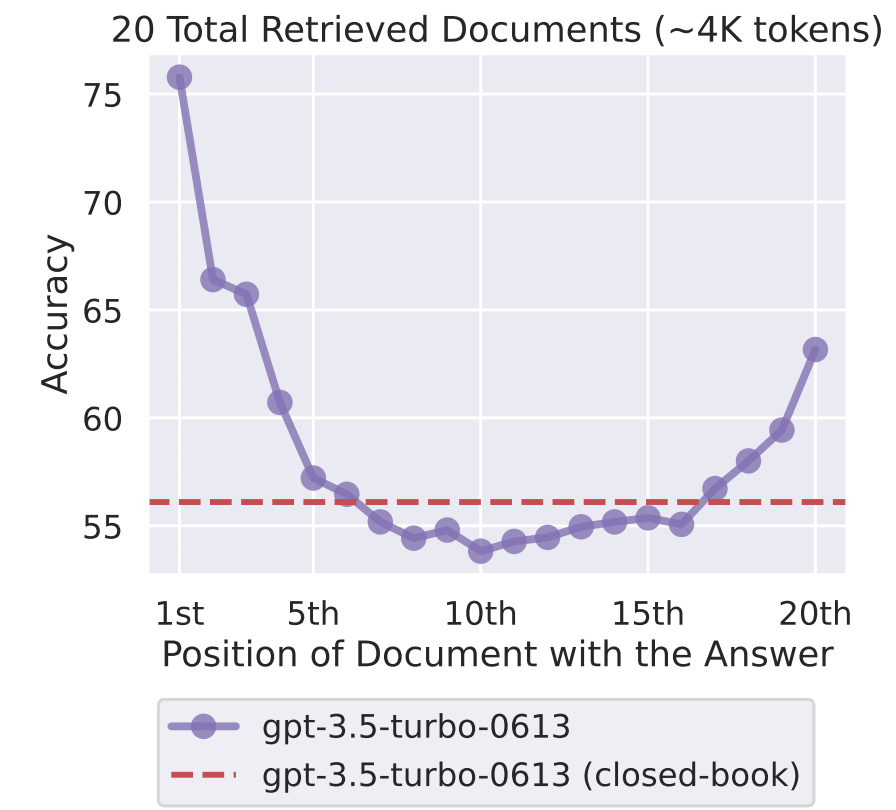
The analogy: A physician reading a 50-page patient chart during a busy shift. They read the first few pages carefully (chief complaint, recent labs). They read the last page carefully (the assessment and plan). The 30 pages in the middle? Skimmed at best. If the critical drug interaction is buried on page 27, it might get missed - not because it wasn’t in the chart, but because attention is finite.
LLMs exhibit the same pattern. The context window is technically huge. Effective attention is not.
Clinical impact: If the chunk about warfarin contraindication in pregnancy lands in position 8 of 15, surrounded by general anticoagulation content, the LLM might generate an answer that overlooks it entirely. The information was retrieved. It was in the context. It was ignored.
The Three Rules
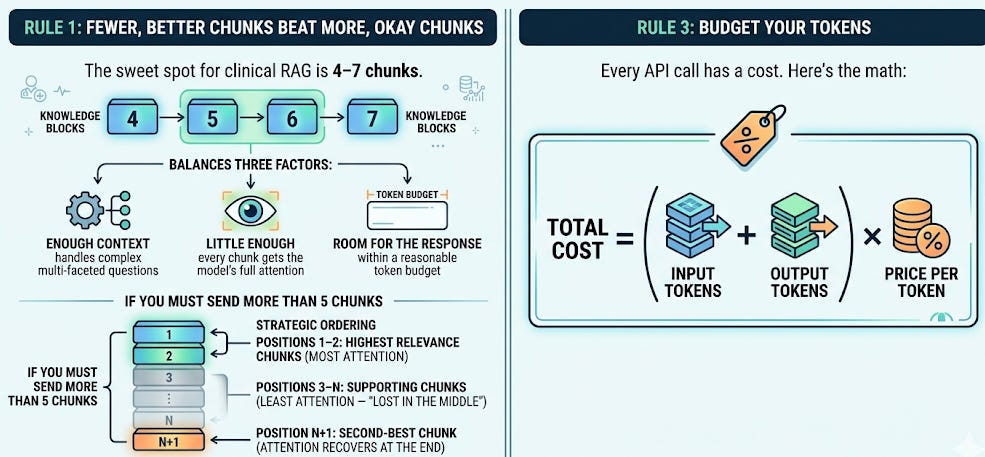
Rule 1: Fewer, Better Chunks Beat More, Okay Chunks
The sweet spot for clinical RAG is 4–7 chunks.
This isn’t arbitrary - it balances three factors:
Enough context to answer complex multi-faceted questions
Little enough that every chunk gets the model’s full attention
Room for the response within a reasonable token budget
The practical approach:
Retrieve broadly (20 chunks), rerank (Day 18), then take the top 5.
If the question is clearly simple (”What is first-line for uncomplicated UTI?”), take the top 3.
If the question is complex and multi-faceted (”Management of HFrEF with CKD stage 4, hyperkalemia, and atrial fibrillation”), consider the top 7.
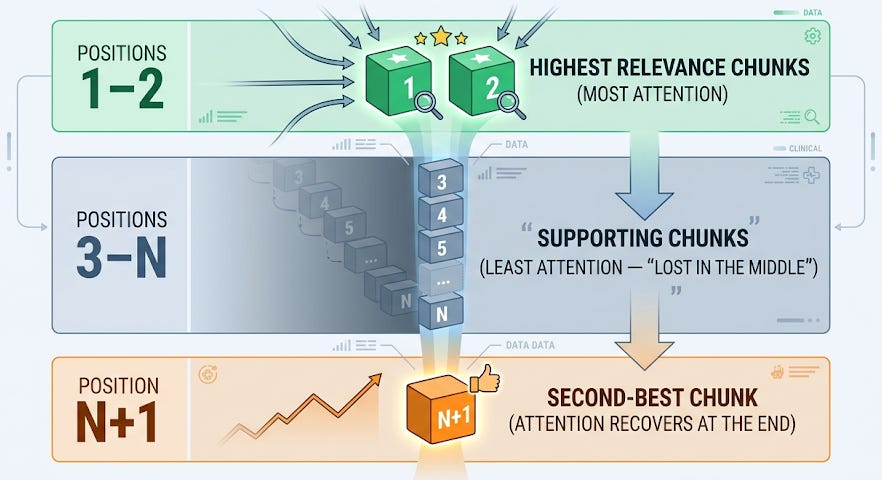
Rule 2: Put the Best Evidence First and Last
If you must send more than 5 chunks, order them strategically to exploit the attention pattern:
python
def order_for_attention(chunks_with_scores):
"""Order chunks to exploit beginning/end attention bias."""
sorted_chunks = sorted(chunks_with_scores, key=lambda x: x[1]) # Best first
if len(sorted_chunks) <= 3:
return sorted_chunks
best = sorted_chunks[:2] # Top 2 → beginning
worst = sorted_chunks[2:-1] # Middle → middle (least attention)
second_best = [sorted_chunks[-1]] # Last strong chunk → end
return best + worst + second_bestThis is a simple reordering: zero cost, zero latency, measurable improvement on longer contexts.
Rule 3: Budget Your Tokens
Every API call has a cost. Here’s the math:

For GPT-5.4 at current pricing, a typical RAG call with 5 chunks, compared with 15 chunks:
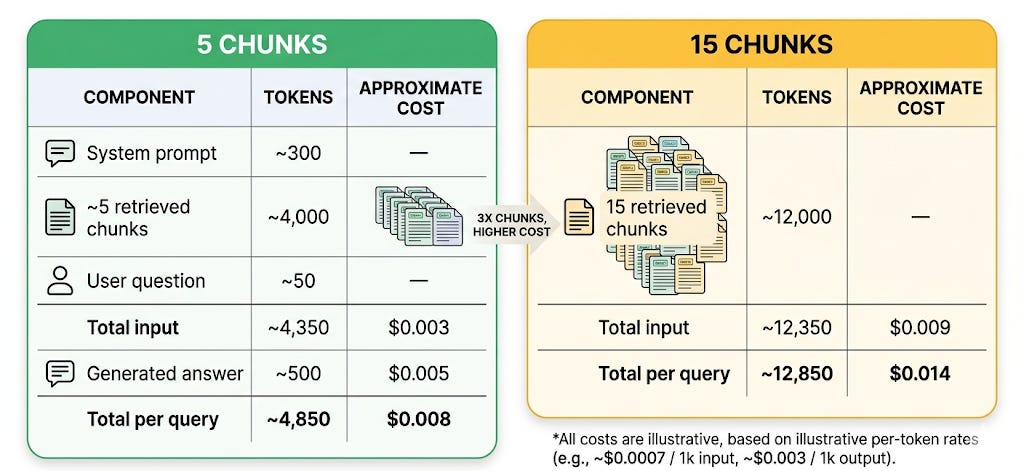
At 1,000 queries/day: $14/day or $420/month. Nearly double the cost, with potentially worse answer quality due to lost-in-the-middle.
This is the rare case where doing less is better on both dimensions.
Dynamic Chunk Selection
Not every query needs the same number of chunks. A simple heuristic:
python
def select_top_k(reranked_chunks, scores):
"""Dynamically choose how many chunks to send."""
top_score = scores[0]
# If the best chunk is very strong, fewer chunks suffice
if top_score > 0.85:
return reranked_chunks[:4]
# If scores are moderate, include more context
if top_score > 0.70:
return reranked_chunks[:6]
# If scores are weak, cast a wider net (but cap at 8)
return reranked_chunks[:8]The analogy: When a cardiologist is very confident in a diagnosis (high score), they order 2–3 targeted tests. When uncertain (moderate score), they order a broader workup. When truly unsure (low score), they cast a wide net - but they don’t order every test in the hospital.
Counting Tokens Before You Send
Always verify your token budget before the API call. Surprises are expensive:
python
import tiktoken
def count_tokens(text, model="gpt-5.4"):
encoding = tiktoken.encoding_for_model("gpt-4o") # Use gpt-4o encoding
return len(encoding.encode(text))
# Check before sending
total = count_tokens(system_prompt + context + query)
print(f"Input tokens: {total}")
if total > 15000:
print("⚠️ Context may be too large — consider fewer chunks")This takes milliseconds and prevents unexpected bills.
Your Takeaway for Today
More context is not better context.
The “Lost in the Middle” phenomenon means LLMs ignore information buried in long contexts.
The sweet spot for clinical RAG is 4–7 chunks, ordered with the best evidence at the beginning and end.
Fewer chunks = better answers + lower cost.
Budget your tokens, order your chunks strategically, and dynamically adjust K based on retrieval confidence.
Coming Tomorrow: Day 21 (Premium Build Project)
BUILD PROJECT: Multi-Source RAG Combining Clinical Notes + Lab Results + Imaging Reports
Tomorrow, paid subscribers get Build Project #3 - a RAG system that ingests multiple data types (clinical notes, lab CSVs, radiology text reports) into a single searchable knowledge base with source-type metadata.
You will use hybrid search, reranking, metadata filtering, and context window management - everything from Week 3, running in one pipeline.
This is the project that proves RAG can handle the messy reality of multi-source clinical data.
→ Subscribe to RAG for Healthcare to get the Day 21 Build Project.
Teodora Szasz, PhD — Senior Clinical Data Scientist | FDA 510(k) AI | Co-author, EchoJEPA