
Day 26: Dual-Level Retrieval - Getting Both the Facts and the Big Picture
RAG for Healthcare | Day 26 of 35 | Free

Yesterday you built a medical knowledge graph from cardiovascular pharmacology content. Today you learn how to query it at the right level of granularity. Because clinical questions aren’t one-size-fits-all.
Query A: “What is the half-life of amiodarone?”
One entity, one fact, one number. The answer is 40–55 days. You need LightRAG to find the specific node, pull the specific property, and return it. Fast, precise, no synthesis required.
Query B: “What are the major challenges in managing antiarrhythmic therapy?”
No single entity answers this. The answer spans multiple drugs (amiodarone, metoprolol, diltiazem), multiple side effects (thyroid dysfunction, pulmonary toxicity, bradycardia), multiple interactions (CYP inhibition, warfarin dose adjustments), and multiple contraindications (HFrEF, heart block). You need LightRAG to traverse the graph broadly, identify patterns, and synthesize.
Same knowledge graph. Same LightRAG instance. Two fundamentally different retrieval strategies.
The Four Query Modes
LightRAG offers four modes. Each activates a different retrieval strategy.
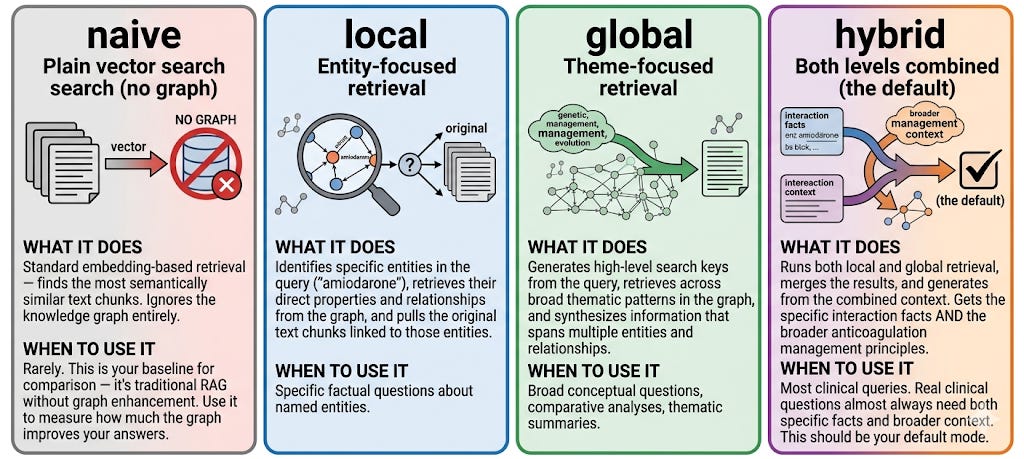
naive: Plain vector search (no graph)
python
result = await rag.aquery("amiodarone half-life", param=QueryParam(mode="naive"))What it does: Standard embedding-based retrieval: finds the most semantically similar text chunks. Ignores the knowledge graph entirely.
The analogy: Reading the textbook page by page until you find the relevant paragraph. No index, no table of contents, just brute-force similarity.
When to use it: Rarely. This is your baseline for comparison - it’s traditional RAG without graph enhancement. Use it to measure how much the graph improves your answers.
Clinical example: “Patient presents with progressive dyspnea and bilateral edema.” A narrative clinical scenario where semantic similarity is sufficient and entity-level precision isn’t needed.
local: Entity-focused retrieval
python
result = await rag.aquery("amiodarone half-life", param=QueryParam(mode="local"))What it does: Identifies specific entities in the query (”amiodarone”), retrieves their direct properties and relationships from the graph, and pulls the original text chunks linked to those entities.
The analogy: Looking up “amiodarone” in the drug handbook index, flipping to that page, and reading the pharmacokinetics section. Direct, precise, no wandering.
When to use it: Specific factual questions about named entities.
Clinical examples:
“What CYP enzyme metabolizes warfarin?” → Finds Warfarin node → follows metabolized_by edge → CYP2C9
“What is the target INR for mechanical mitral valves?” → Finds Warfarin node → follows monitored_by edge → INR → reads target range
“Is diltiazem contraindicated in HFrEF?” → Finds Diltiazem node → follows contraindicated_in edge → HFrEF → Yes
“What monitoring does amiodarone require?” → Finds Amiodarone node → follows all monitoring-related edges
global: Theme-focused retrieval
python
result = await rag.aquery(
"What are the major challenges in managing antiarrhythmic therapy?",
param=QueryParam(mode="global"),
)What it does: Generates high-level search keys from the query, retrieves across broad thematic patterns in the graph, and synthesizes information that spans multiple entities and relationships.
The analogy: Asking a senior cardiologist to give a 5-minute overview of antiarrhythmic challenges. They draw from their knowledge of multiple drugs, multiple patients, multiple trials - synthesizing a narrative that no single page in the textbook contains.
When to use it: Broad conceptual questions, comparative analyses, thematic summaries.
Clinical examples:
“How do genetic factors influence cardiovascular drug dosing?” → Traverses CYP2C9 polymorphisms → VKORC1 → CYP2D6 → synthesizes the pharmacogenomics theme
“What are the common side effect patterns across antiarrhythmics?” → Traverses amiodarone toxicities + metoprolol bradycardia + diltiazem negative inotropy → identifies patterns
“How has heart failure treatment evolved with SGLT2 inhibitors?” → Traverses dapagliflozin → DAPA-HF → DELIVER → HFrEF + HFpEF → synthesizes the clinical shift
hybrid: Both levels combined (the default)
python
result = await rag.aquery(
"My patient is on warfarin and needs amiodarone - what should I know?",
param=QueryParam(mode="hybrid"),
)What it does: Runs both local and global retrieval, merges the results, and generates from the combined context. Gets the specific interaction facts AND the broader anticoagulation management principles.
The analogy: The consulting cardiologist who both looks up the specific interaction in the drug database (local) AND draws on their clinical experience with anticoagulation management (global) to give you a complete, nuanced answer.
When to use it: Most clinical queries. Real clinical questions almost always need both specific facts and broader context. This should be your default mode.
Clinical examples:
“Should I start dapagliflozin in a patient with HFrEF and eGFR 22?” → Local: dapagliflozin eGFR threshold (≥20) → Global: SGLT2i evidence in CKD + HF
“How should I manage anticoagulation when adding amiodarone?” → Local: warfarin-amiodarone interaction details → Global: anticoagulation monitoring principles
“What rate control options are safe in heart failure?” → Local: metoprolol (safe in HFrEF) and diltiazem (contraindicated in HFrEF) → Global: rate control strategy in HF
How Dual-Level Retrieval Works Under the Hood
When you query in hybrid mode, LightRAG runs two parallel retrieval pipelines:
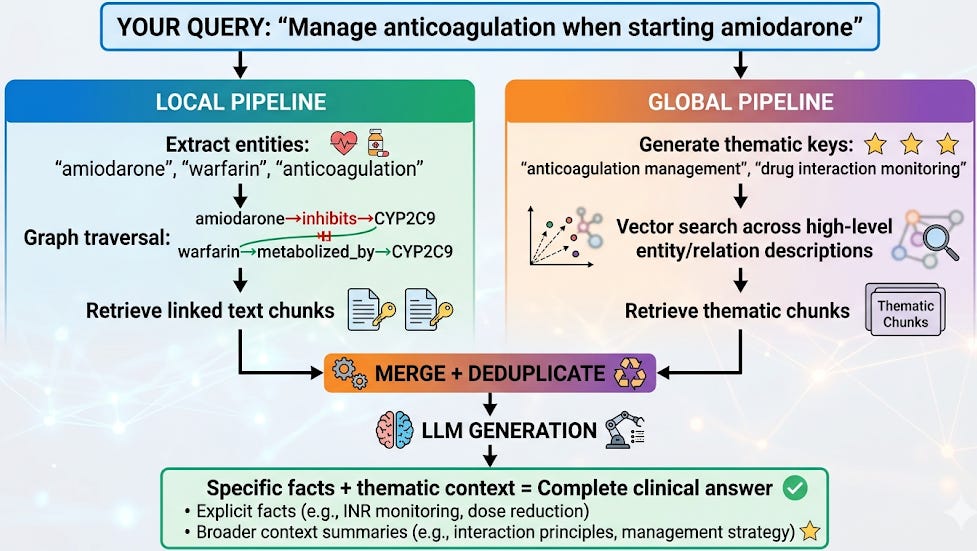
The merge step deduplicates overlapping content (both pipelines might retrieve the same amiodarone chunk) and orders results by relevance.
The LLM then generates from this combined context: getting both the “reduce warfarin by 30–50%” fact AND the “monitor INR within 1 week and reassess at steady state” management principle.
The Decision Cheat Sheet
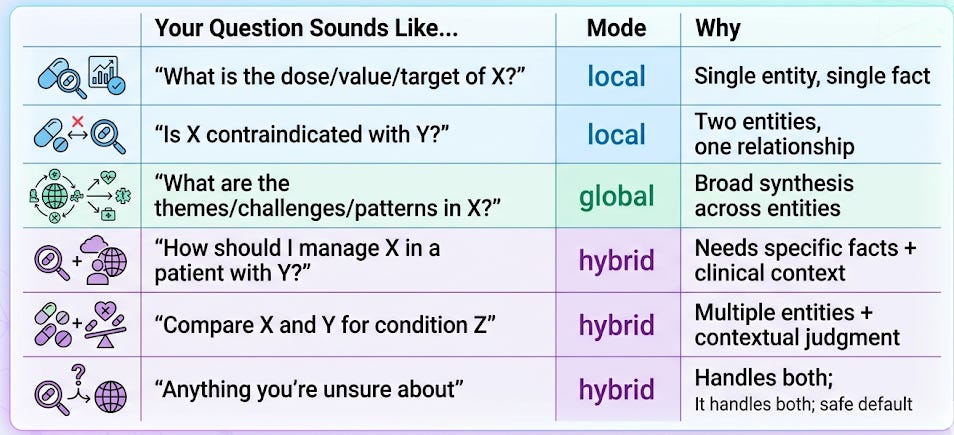
The practical rule: When in doubt, use hybrid. It’s slightly slower than local or global alone (two retrieval passes instead of one), but the latency difference is typically under 200ms, negligible for clinical use. The accuracy gain from combining both levels consistently outweighs the minor speed cost.
Your Takeaway for Today
LightRAG’s four query modes give you precision when you need it (local), synthesis when you need it (global), and both when you need both (hybrid).
Local mode traverses specific entities and relationships for factual answers.
Global mode searches across thematic patterns for broad synthesis.
Hybrid mode, your default, combines both for the complete clinical picture. Match the mode to the question type, and your knowledge graph answers at exactly the right level of granularity.
Coming Tomorrow: Day 27
Visualizing Your Medical Knowledge Graph
You have built a knowledge graph and queried it at multiple levels. Tomorrow you see it. You will visualize the entity-relationship network, identify clusters, trace multi-hop paths, and produce visuals that make the knowledge structure tangible to clinicians and stakeholders who’ve never heard of a “knowledge graph.” The picture that makes your CMIO say “I get it.”
→ Subscribe to RAG for Healthcare so you don’t miss Day 27.
Teodora Szasz, PhD | Senior Clinical Data Scientist | FDA 510(k) AI | Co-author, EchoJEPA