
Day 4: Dataset Alchemy - Preparing Data for Fine-Tuning
7 Days to LLM Mastery — Your $200K AI Bootcamp, FREE

Welcome back to the Standout Systems newsletter. You now have the tools (Days 1-3). Today, you’ll learn what separates amateur fine-tuners from professionals: the data.
The Truth Nobody Wants to Hear
You can have:
The best GPU setup ✓
Perfect quantization ✓
Optimal LoRA configuration ✓
And still end up with a model that:
Never stops generating
Outputs garbage
Ignores your instructions
The problem isn’t the model. It’s your data.
I’ve seen engineers spend weeks debugging training code, only to discover their dataset was formatted wrong. One missing token can ruin everything.
Today, you’ll learn exactly how to format data so your fine-tuning actually works.
What You’re Getting Today
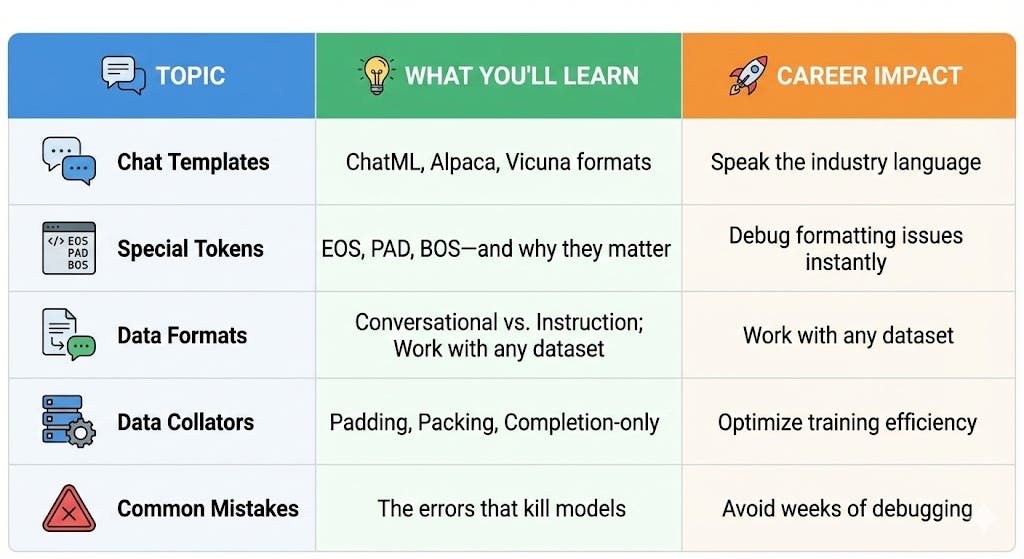
The Big Picture: Why Formatting Matters
Before instruction-tuning, language models were simple. You gave them text, they predicted the next token, and they kept rambling until you stopped them.
Prompt: "The capital of Argentina is"
Model: "Buenos Aires, located at the southeastern coast of South America..."
The model doesn’t know when to stop. It just... keeps going.
After instruction-tuning, models learned a crucial skill: knowing when to shut up.
Prompt: "What is the capital of Argentina?"
Model: "Buenos Aires."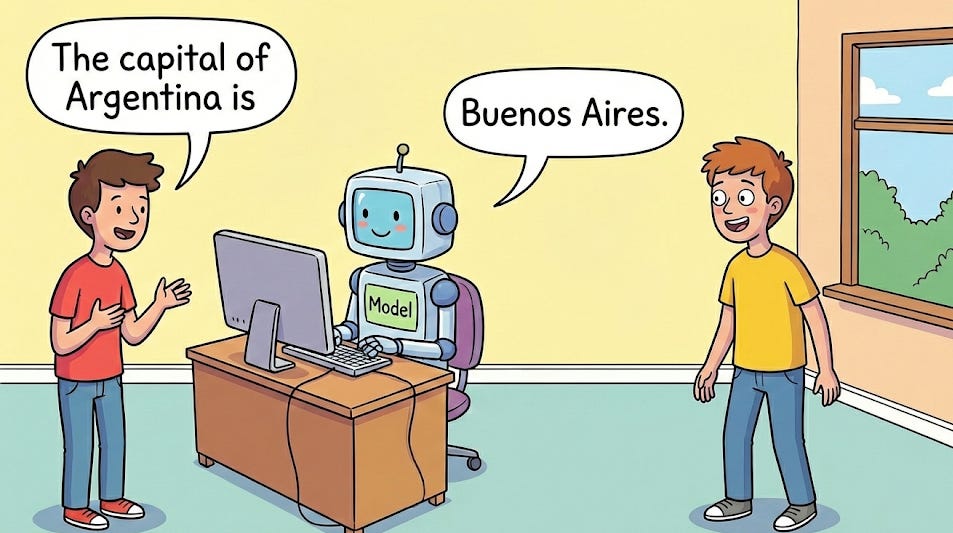
The difference? Special tokens and templates that teach the model:
When the user is asking something
When the assistant should respond
When to stop generating
The Anatomy of a Chat Template
Every chat template has three critical components:
