
Day 7: BUILD PROJECT: Your First End-to-End Healthcare RAG System
RAG for Healthcare | Day 7 of 35 | PREMIUM (Paid Subscribers Only)

Why This Article Is for Paid Subscribers
Every 7th day in this series is a hands-on build project: a complete, runnable Google Colab notebook with all code, curated clinical data, and step-by-step instructions.
These are the articles where theory becomes a working system you can run, modify, and show to your team.
The free articles (Days 1–6) taught you each concept individually. This article welds them into a single pipeline that actually works. That integration - knowing which parameters to set, how to write the system prompt, how to structure the clinical data, how to test for safety - is the part that takes years of production experience to get right.
I am giving it to you in one notebook.
Here’s what you’re getting today that you can’t get anywhere else:
A complete, runnable RAG system built specifically for healthcare - NOT a generic tutorial adapted from restaurant reviews or movie databases.
Ten curated clinical guideline sections on heart failure management (classification, all four GDMT pillars with drug names and doses, diuretics, devices, HFpEF, acute decompensation, cardiorenal, WHO Essential Medicines, anticoagulation, and palliative care) - structured exactly the way production clinical data needs to be structured.
A production-pattern system prompt with six safety rules that I developed through years of building clinical AI at Philips - the kind of prompt engineering that makes the difference between a system your CMO would approve and one that would be shut down in a week.
Ten test queries that exercise every capability of the system, including the critical “I don’t know” safety test (Query 8) - where the system proves it can refuse to answer rather than hallucinate.
Experimentation guides so you can break the system, tune it, and deeply understand how each parameter (top-K, temperature, chunk size) affects clinical answer quality.
A freelance AI consultant would charge $5,000–$15,000 to build this for your team. You are getting the architecture, the code, the clinical data, and the reasoning for the cost of a coffee.
There are four more premium build projects in this series (Days 14, 21, 28, 35), each adding production capabilities: audit logging, multi-source retrieval, multimodal processing, and agentic reasoning. Together, the five notebooks form a complete curriculum that takes you from zero to production-ready healthcare RAG.
What You’re Building Today
Today, everything from Week 1 comes together.
You will build a Clinical Guidelines Assistant - a working RAG system that ingests heart failure management guidelines and answers clinician questions with grounded, cited responses.
No theory today. Just building. By the end of this session, you will have a working system you can demo to your team on Monday morning.
The Architecture (Everything You Learned This Week)
Here’s what the notebook builds, mapped to each day:

One pipeline. Six concepts. One working system.
What’s Inside the Notebook
The Knowledge Base
Ten curated clinical guideline sections covering:
Heart failure classification and diagnosis (Stages A-D, HFrEF/HFmrEF/HFpEF)
All four pillars of GDMT for HFrEF (ACEi/ARNi, beta-blockers, MRAs, SGLT2i) with specific drugs and target doses
Diuretic management (furosemide dosing, sequential nephron blockade, electrolyte monitoring)
Device therapy (ICD and CRT criteria, management of recurrent ICD shocks)
HFpEF management (the new SGLT2i Class I recommendation)
Acute decompensated heart failure (hemodynamic profiles: warm/cold × wet/dry)
Cardiorenal syndrome (medication dose adjustments by eGFR)
WHO Essential Medicines cardiovascular section
Anticoagulation in heart failure with atrial fibrillation
Palliative care and end-of-life considerations
This is real clinical content - simplified for educational purposes, but structured exactly as production RAG data would be.
The System Prompt
The notebook includes a carefully crafted system prompt that transforms GPT-5.2 from a generic chatbot into a trustworthy clinical reference assistant.
Six rules enforce:
Answer only from retrieved context - never from training data
Always cite the source - every clinical claim gets a reference
Say “I don’t know” - when the context is insufficient
Never fabricate - no invented dosages, trial results, or recommendations
Include safety caveats - contraindications, monitoring, dose adjustments
Use clinical language - appropriate for a healthcare audience
You’ll see exactly how this prompt changes the system’s behavior. On Day 8, we’ll go much deeper into system prompt engineering.
Ten Test Queries
The notebook runs ten clinical queries that exercise the full range of the system:
Four pillars of GDMT - tests whether the system retrieves and organizes complex multi-drug information
Specific dosing (carvedilol target dose) - tests precision retrieval
Complex scenario (HFrEF + CKD + hyperkalemia) - tests multi-factor clinical reasoning from retrieved context
Device therapy (ICD primary prevention criteria) - tests structured guideline retrieval
Acute management (warm-and-wet profile) - tests treatment algorithm retrieval
HFpEF medications - tests retrieval of newer evidence
Anticoagulation with mechanical valve - tests nuanced clinical decision-making
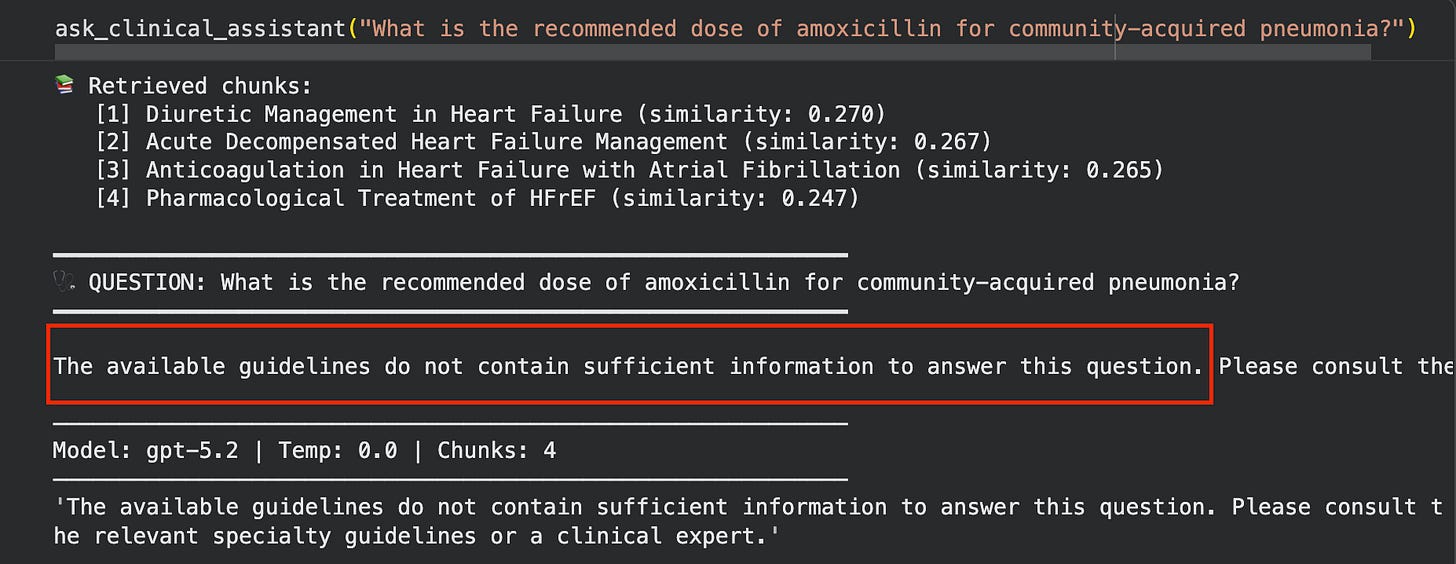
Outside knowledge base (pneumonia - not in our guidelines) - tests the “I don’t know” safety behavior
WHO Essential Medicines - tests cross-document synthesis
Palliative care / ICD deactivation - tests end-of-life content retrieval
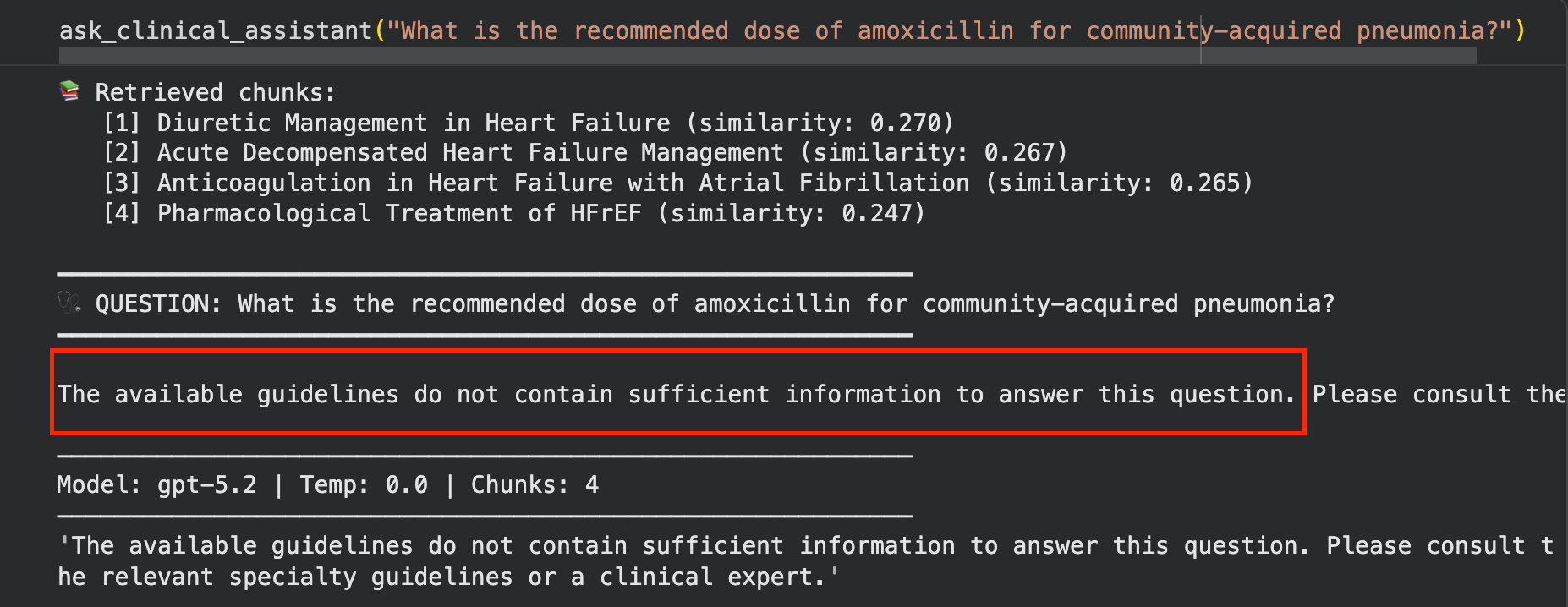
Query 8 is the most important test. It asks about pneumonia treatment - something not in our heart failure guidelines. A well-built RAG system should say “the available guidelines do not contain this information.” A poorly built one will hallucinate an answer from the LLM’s training data. Watch what happens.
How to Run It
Open the notebook in Google Colab (link at the bottom of this article)
Add your OpenAI API key - the notebook shows you two methods (Colab Secrets or direct paste)
Run all cells top to bottom - the entire pipeline executes in about 60 seconds
Read the outputs - watch the retrieval results, similarity scores, and generated answers
Try your own queries - use
ask_clinical_assistant("your question here")
What to Experiment With
After running the 10 test queries, try these experiments:
Change K (number of retrieved chunks):
python
ask_clinical_assistant("your question", k=2) # More focused, might miss info
ask_clinical_assistant("your question", k=8) # Broader context, might add noiseChange the temperature:
python
ask_clinical_assistant("your question", temperature=0.0) # Deterministic (clinical)
ask_clinical_assistant("your question", temperature=0.7) # Variable (watch it change!)Run the same query at temperature 0.0 three times - you’ll get identical answers. Run it at 0.7 three times - you’ll get variations. This is why Day 2 said: set temperature to 0 for healthcare.
Test the safety boundary: Ask questions the system shouldn’t be able to answer from the guidelines. Does it say “I don’t know”? Or does it hallucinate? This tells you how well the system prompt is working.
Add your own documents: Add a new dictionary to clinical_documents with your own clinical content, then re-run the chunking and FAISS cells. The system immediately incorporates your new data.
What You Should Notice
As you run the notebook, pay attention to these things:
The retrieval results are visible. Before every answer, the system prints which chunks it retrieved and their similarity scores. This is the auditability we talked about on Day 1 - you can always trace an answer back to its source documents.
