
How ChatGPT Actually Works (Explained Like You're a Smart 12-Year-Old)
The "Transformer" architecture that changed everything — finally explained without the math that makes your eyes glaze over.

I’m going to let you in on a secret.
ChatGPT isn’t magic. It’s not sentient. It doesn’t “understand” you.
It’s doing one thing — over and over, billions of times:
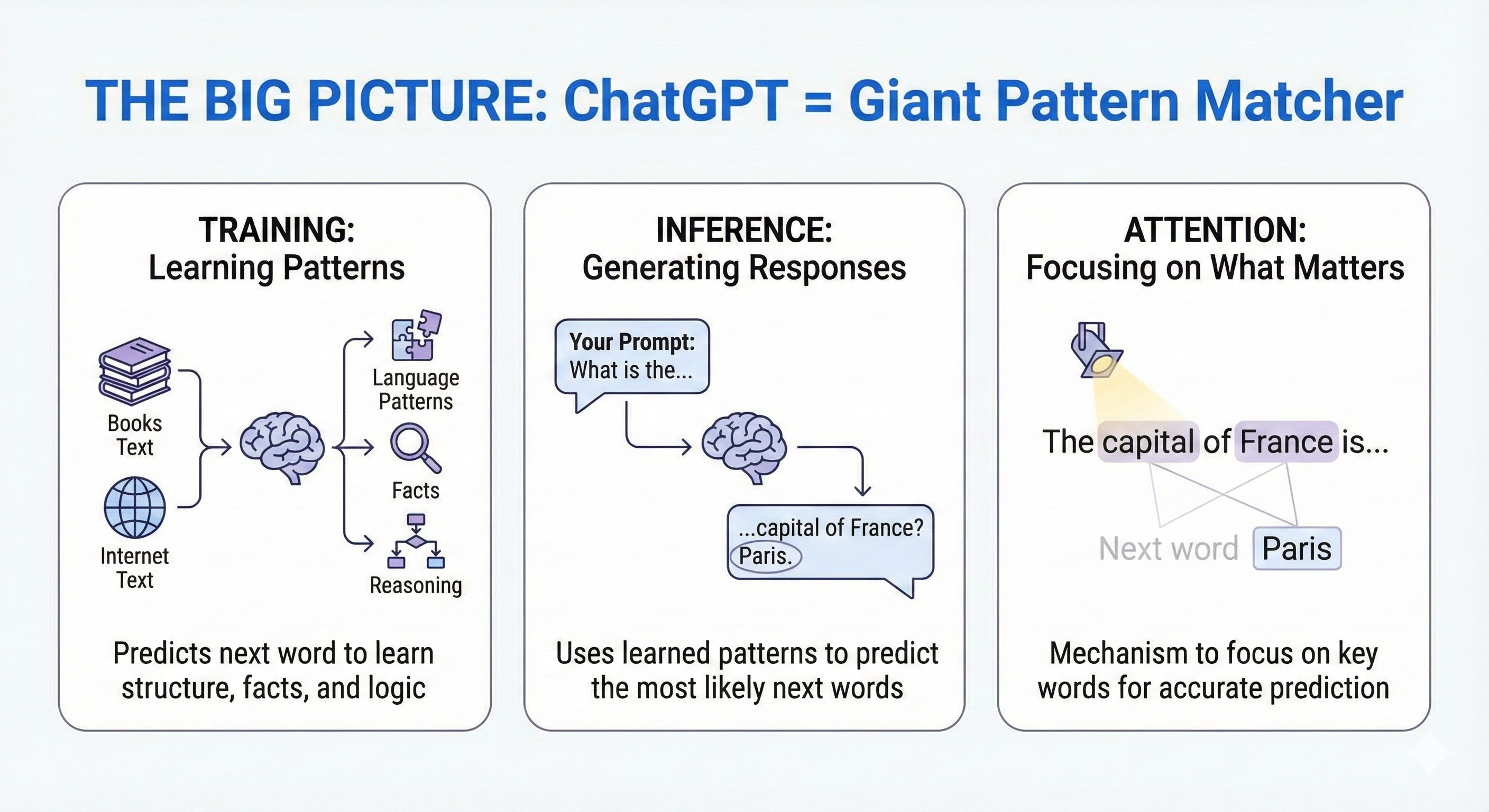
Predicting the next word.
That’s it. When you ask ChatGPT “What’s the capital of France?”, it’s not “thinking.” It’s predicting: “Given everything I’ve seen, what word most likely comes next?”
The → capital → of → France → is → Paris → .
The architecture that makes this possible is called a Transformer. And once you understand it, you’ll never look at AI the same way again.
The Problem Transformers Solved (A Story)
Before 2017, AI read text the way you might read while walking on a tightrope.
One word at a time. In order. Very carefully.
These were called Recurrent Neural Networks (RNNs), and they had a fatal flaw:
Imagine reading this sentence:
“The cat, which was sitting on the mat that was in the living room of the house that Jack built, was hungry.”

By the time you reach “was hungry,” an RNN has almost forgotten what “was hungry” refers to. The cat? The mat? The house? Jack?
The information from “the cat” has been passed through so many steps that it’s faded like a game of telephone.
Transformers fixed this by letting the model look at all words at once.
Instead of reading left to right, word by word, transformers can see the entire sentence simultaneously and decide: “To understand ‘was hungry,’ I should pay attention to ‘the cat’ — not ‘the mat’ or ‘Jack’.”
This ability to look everywhere at once and decide what matters is called attention.
And it changed everything.
The Big Idea: Attention Is All You Need
In 2017, Google researchers published a paper with a slightly provocative title: “Attention Is All You Need.”
They were right.
Here’s the core insight in plain English:
When predicting the next word, not all previous words matter equally.
Consider: “The animal didn’t cross the street because it was too tired.”
What does “it” refer to? The animal. Not the street.
How do you know? Because “tired” is something an animal can be, not something a street can be.
A transformer figures this out by computing attention scores — basically asking: “For each word I’m predicting, how much should I pay attention to every other word?”
"The animal didn't cross the street because it was too tired"
↑
When predicting what "it" means...
Attention scores:
"The" → 0.02 (low)
"animal" → 0.85 (HIGH — this is what "it" refers to!)
"didn't" → 0.01 (low)
"cross" → 0.02 (low)
"the" → 0.01 (low)
"street" → 0.05 (low — streets can't be tired)
"because" → 0.02 (low)
"it" → 0.01 (low)
"was" → 0.01 (low)The model learns these attention patterns from billions of examples. Nobody programmed it to know that animals can be tired and streets can’t. It learned this from seeing language.
The Three Magic Ingredients: Query, Key, Value
Here’s where it gets beautiful.
Every word in a sentence gets transformed into three things:
🔍 Query (Q): “What am I looking for?” 🔑 Key (K): “What do I contain?” 💎 Value (V): “What do I actually contribute?”
Think of it like a library:
You walk in with a Query: “I need information about tired things”
Each book has a Key on its spine: “Animals,” “Streets,” “Buildings”
The Value is the actual content inside the book
The attention mechanism:
Compares your Query to every Key
Finds the best matches
Returns a weighted blend of their Values
In code, it’s shockingly simple:
python
# The entire attention mechanism in ~10 lines
def attention(Q, K, V):
# How well does each Query match each Key?
scores = Q @ K.transpose() / sqrt(d_k)
# Convert scores to probabilities (must sum to 1)
weights = softmax(scores)
# Weighted combination of Values
output = weights @ V
return outputThat’s it. That’s the core of ChatGPT, GPT-4, Claude, Gemini — every major language model.
Self-Attention: The Word Cocktail Party
Here’s the really clever part: in a transformer, every word creates its own Query, Key, and Value.
Then every word computes attention against every other word.
Imagine a cocktail party where every person (word) asks every other person: “How relevant are you to me?”
Sentence: "I love Paris in the spring"
"I" asks: "How much attention should I pay to [love, Paris, in, the, spring]?"
"love" asks: "How much attention should I pay to [I, Paris, in, the, spring]?"
"Paris" asks: "How much attention should I pay to [I, love, in, the, spring]?"
... and so onThis creates a rich web of relationships. “Love” might pay attention to “I” (who’s doing the loving) and “Paris” (what’s being loved). “Spring” might pay attention to “Paris” (they often go together).
This all happens in parallel — not one word at a time. That’s why transformers are fast and can handle long documents.
Multi-Head Attention: Looking at Things Different Ways
One attention pattern isn’t enough.
Consider: “The bank was steep, so I sat on the bank to rest.”
The word “bank” has two meanings:
“steep bank” → riverbank (geographical)
“sat on the bank” → could be riverbank or even bench
A single attention pattern might miss this nuance.
So transformers use multi-head attention — multiple attention mechanisms running in parallel, each looking for different patterns:
Head 1: Looking for subject-verb relationships
Head 2: Looking for adjective-noun relationships
Head 3: Looking for coreference (what does "it" refer to?)
Head 4: Looking for semantic similarity
... (typically 8-16 heads)Each head learns to pay attention to different things. Then their outputs are combined.
It’s like having 8 different people read the same sentence, each with a different lens, then pooling their insights.
The Full Transformer Architecture (Simplified)
Here’s how it all fits together:
┌─────────────────────────────────────────────────┐
│ INPUT: "I love" │
└────────────────────┬────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ EMBEDDING + POSITION │
│ Convert words to vectors, add position info │
└────────────────────┬────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ TRANSFORMER BLOCK (x96) │
│ ┌───────────────────────────────────────────┐ │
│ │ Multi-Head Self-Attention │ │
│ │ (words attend to other words) │ │
│ └───────────────────────────────────────────┘ │
│ ┌───────────────────────────────────────────┐ │
│ │ Feed-Forward Network │ │
│ │ (process each position independently) │ │
│ └───────────────────────────────────────────┘ │
└────────────────────┬────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ OUTPUT PROBABILITIES │
│ "Paris": 0.15, "pizza": 0.08, "you": 0.12... │
└────────────────────┬────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ SAMPLE NEXT WORD: "Paris" │
└─────────────────────────────────────────────────┘GPT-4 has roughly 96 of these transformer blocks stacked on top of each other. Each block refines the representation, building increasingly abstract understanding.
The Secret Sauce: Training on the Internet
The architecture is only half the story. The other half is what it learned from.
ChatGPT was trained on a simple task: predict the next word.
Given: “The Eiffel Tower is located in ____” Predict: “Paris”
Given: “To be or not to ____” Predict: “be”
Do this billions of times across hundreds of billions of words from books, websites, Wikipedia, and more.
Over time, to predict words accurately, the model had to learn:
Facts: “Paris is in France”
Grammar: “She walks” not “She walk”
Reasoning: “If A implies B, and A is true, then...”
Style: Formal vs. casual, poetic vs. technical
And much more
Nobody programmed these abilities. They emerged from next-word prediction.
This is the magic — and the limitation. ChatGPT doesn’t “know” things the way you do. It knows what words tend to follow other words.
How ChatGPT Generates Responses
When you ask ChatGPT something, here’s what happens:
Step 1: Your input gets tokenized (split into pieces)
"What is the capital of France?"
→ ["What", " is", " the", " capital", " of", " France", "?"]Step 2: Tokens become vectors (embeddings)
Step 3: Vectors pass through 96 transformer layers, each applying self-attention and feed-forward processing
Step 4: The final layer outputs probabilities for every possible next token
"The": 0.02
"Paris": 0.45 ← highest!
"France": 0.08
"capital": 0.03
...Step 5: Sample the next token (often just pick the highest, but with some randomness)
Step 6: Append “Paris” to the input, repeat from Step 1
Step 7: Keep going until a stop token is generated
That’s it. ChatGPT generates text one token at a time, each time looking at everything that came before.
The Masked Attention Trick (Why ChatGPT Can’t See the Future)
One crucial detail: when generating text, ChatGPT can only attend to previous words, not future ones.
Why? Because future words don’t exist yet!
This is called masked attention or causal attention:
Generating: "I love Paris in the ___"
When predicting the blank, the model can see:
✓ "I"
✓ "love"
✓ "Paris"
✓ "in"
✓ "the"
✗ [future words blocked]The mask prevents “cheating” by looking ahead:
python
# Create a mask that blocks future positions
mask = [[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]
# 1 = can attend, 0 = blockedBERT, another famous transformer, doesn’t use this mask — it can see the whole sentence. That’s great for understanding text but means it can’t generate text naturally.
Why Transformers Dominate Everything
Transformers aren’t just for text. They’ve taken over:
🖼️ Vision: Vision Transformers (ViT) now beat CNNs on image classification 🎵 Audio: Whisper (speech recognition) uses transformers 🧬 Biology: AlphaFold 2 (protein structure prediction) uses transformers 🎮 Games: Decision Transformer for reinforcement learning 🔬 Science: Transformers for drug discovery, weather prediction, code generation
Why such dominance?
Parallelization: Unlike RNNs, transformers process all positions simultaneously (GPUs love this)
Long-range dependencies: Attention can directly connect distant words
Scalability: More data + more parameters = better performance (so far)
Transfer learning: Pre-train once, fine-tune for everything
The Interview Questions You’ll Get
“Explain how transformers work”
Your answer: “Transformers process sequences using self-attention, where each position computes attention scores with every other position to determine relevance. This is done using Query, Key, Value projections — the Query asks what information is needed, Keys indicate what information each position contains, and Values provide the actual content. Multi-head attention runs several attention mechanisms in parallel to capture different relationship types. Unlike RNNs, transformers process all positions simultaneously, enabling better parallelization and handling of long-range dependencies.”
“What’s the difference between GPT and BERT?”
Your answer: “Both are transformer-based, but they differ in training objective and attention pattern. GPT uses causal (masked) attention and is trained on next-token prediction — it only sees past context. BERT uses bidirectional attention and is trained on masked language modeling — it sees the full context and predicts masked words. GPT is better for generation tasks; BERT is better for understanding tasks like classification and question answering.”
“Why do transformers scale better than RNNs?”
Your answer: “Three reasons: (1) Parallelization — RNNs must process tokens sequentially, while transformers process all tokens simultaneously. (2) Long-range dependencies — RNNs suffer from vanishing gradients over long sequences; transformers can directly connect any two positions via attention. (3) Architecture simplicity — transformers use the same attention mechanism throughout, making them easier to scale with more layers and parameters.”
The Complete Mental Model
Here’s how to think about ChatGPT:
It’s not thinking. It’s not reasoning. It’s not understanding.
It’s pattern matching at a scale and sophistication that looks like intelligence.
And that’s both less magical and more magical than you thought.
Your Action Items
Implement self-attention from scratch (it’s ~20 lines). Nothing beats building it yourself for understanding.
Visualize attention patterns: Tools like BertViz let you see what words attend to what. It’s illuminating.
Play with the temperature parameter: Try generating with temperature=0.1 vs temperature=1.0. See how randomness affects output.
Know your vocabulary: Query, Key, Value, multi-head attention, masked attention, positional encoding, feed-forward network. Be fluent.
Understand the limitations: ChatGPT is a pattern matcher trained on past text. It can’t truly reason, doesn’t have beliefs, and confidently generates plausible-sounding nonsense.
The Bottom Line
Transformers are the architecture that finally made AI “work” for language.
The core idea — attention — is beautifully simple: let every word decide which other words matter for its meaning.
Scale this up with billions of parameters, train on trillions of words, and you get ChatGPT.
Not magic. Not intelligence. Just extremely sophisticated next-word prediction.
But sometimes, that’s enough to change the world.
Found this helpful? Share it with someone curious about AI.
Questions? Reply directly — I read every response.
Tomorrow: Fine-Tuning vs. Prompting — When to teach the model vs. when to just ask better questions.
Teodora coaches data scientists and ML engineers to land roles at top tech companies. Learn more at teodora.coach
This explanation of AI as “next-word prediction” is accurate — and the article does a strong job breaking down attention, tokens, and how the system actually works.
But there’s one layer missing.
Everything described here happens inside a single pass:
tokens → attention → probabilities → next word.
In real use, though, that process doesn’t happen once.
It happens across turns — with interaction.
So a more complete way to say it is:
“It predicts the next word under continuously updated constraints imposed by interaction.”
Because the user isn’t just providing input.
They are:
• reinforcing or rejecting outputs
• shifting tone and framing
• applying pressure for precision
• and shaping what the model prioritizes next
The model computes probabilities.
The interaction reshapes them over time.
That layer isn’t in most explanations — but it’s where the system actually becomes useful.