
Your attacker is already running an LLM over your code. You should too.
The same model that drafts your phishing email will read your whole codebase. The defender's playbook starts with running it first.

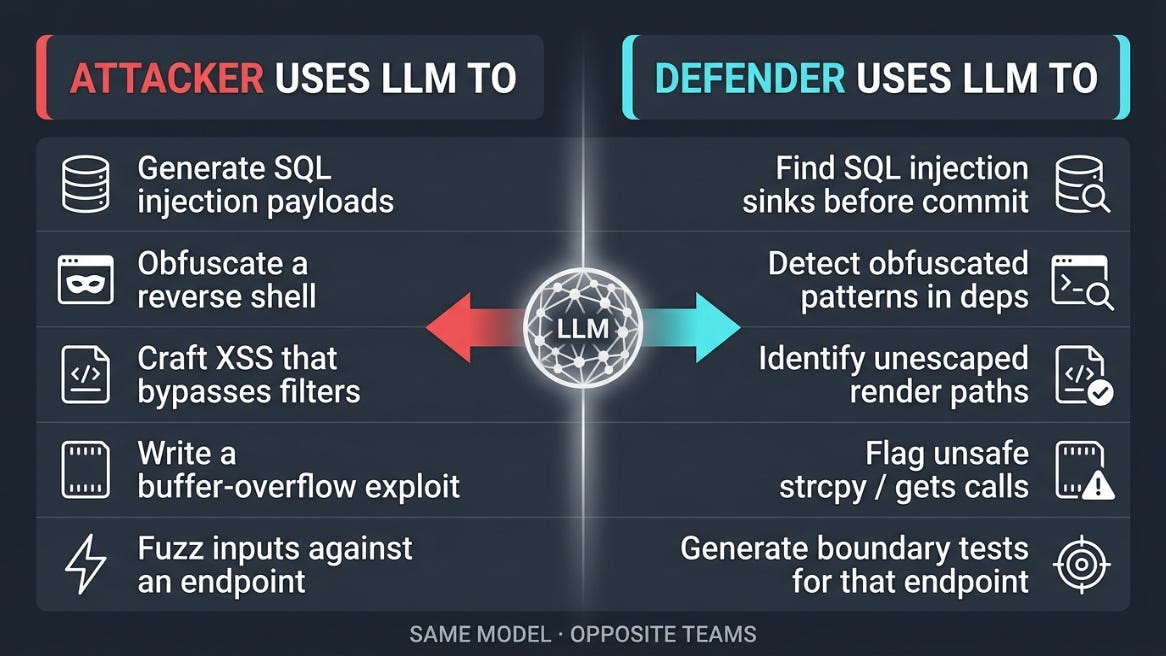
A junior attacker with thirty dollars and an LLM now produces working SQL injection, XSS, command-injection, and reverse-shell payloads on demand.
The skill floor for offence dropped sometime in the last eighteen months.
The skill floor for defence did not move at all.
That asymmetry is the post.
The shift, in one paragraph
Pasting your source code into an LLM and asking:
“what’s wrong with this from a security perspective”
Is now a credible alternative to a junior pentester for the first half of a code review.
It will miss things. It will hallucinate.
But on classic OWASP-class bugs in fewer than 500 lines of code, it lands findings the in-house team frequently does not.
The attacker is already doing this against your public repos, your leaked branch dumps, and any code you ship to clients.
The only question is whether you run it on your own code first.
The OWASP map
Here is what an LLM reliably catches on a small file, and what it does not.

Reliable on small files: SQL injection (A03), reflected XSS (A03), command injection (A03), path traversal (A01), hardcoded secrets (A07), insecure deserialisation (A08), missing authn/authz checks (A01), debug flags in production (A05).
Unreliable: business-logic flaws, race conditions, multi-file authorisation gaps, anything that requires understanding a request flow across a dozen handlers, and most cryptographic subtleties beyond “you used MD5.”
This is not a replacement for a real audit. It is a force multiplier on the boring 70% an audit would have caught anyway, before it gets near production.
The defender’s flip
Every offensive use the attacker has: payload generation, exploit drafting, obfuscation, fuzz-input synthesis, has a one-line defensive mirror.
See the GitHub repo for post 5 for the full code. The script is sixty lines.
Grab the code
git clone https://github.com/DoraSzasz/ml-for-defenders.git
cd ml-for-defenders/05-llm-appsec
pip install -r requirements.txt
export ANTHROPIC_API_KEY=sk-ant-...
Two files in there:
llm_codereview.py: sixty-line Claude-powered code reviewer.
Returns structured JSON findings with line, severity, OWASP category, why, and fix.
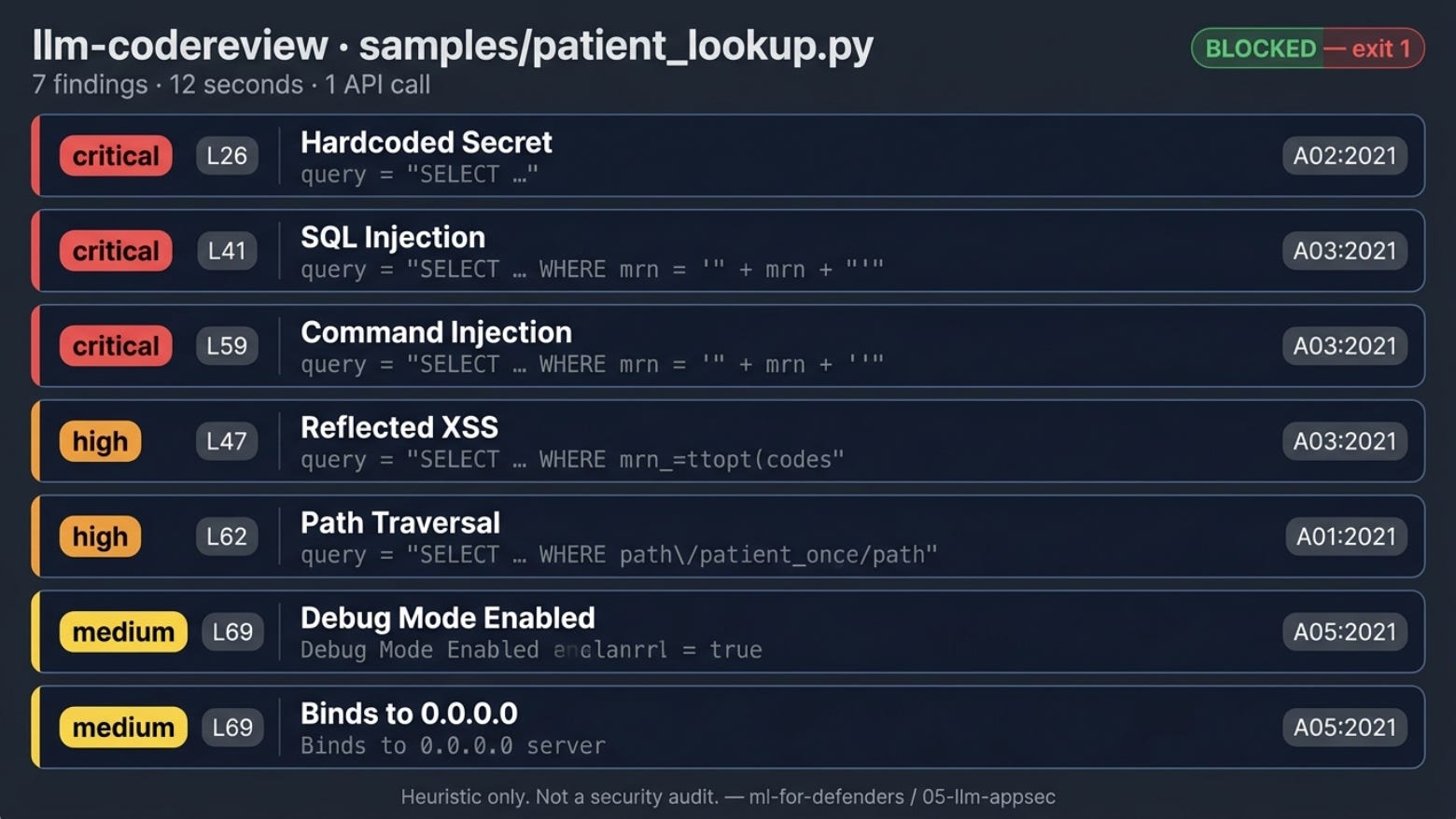
Exits non-zero if any HIGH or CRITICAL is found, so it drops straight into pre-commit or CI.samples/patient_lookup.py: a deliberately vulnerable forty-line clinical Flask snippet with five planted bugs across the OWASP Top 10. Useful both as a demo target and as a sanity check after you change the prompt.
Run it
python llm_codereview.py samples/patient_lookup.pyOn the demo file you should see findings for SQL injection, reflected XSS, command injection, path traversal, hardcoded secret, and probably debug=True and host=0.0.0.0 as bonus calls. Twelve seconds, one API call.

Now point it at your own code:
python llm_codereview.py app/routes/patient.pyThe script exits 1 if it finds anything HIGH or CRITICAL, so you can wire it into a pre-commit hook or your CI pipeline today:
# .github/workflows/llm-review.yml (excerpt)
- name: LLM AppSec review
run: python llm_codereview.py app/routes/${{ matrix.file }}
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
Where this fits in your SSDLC
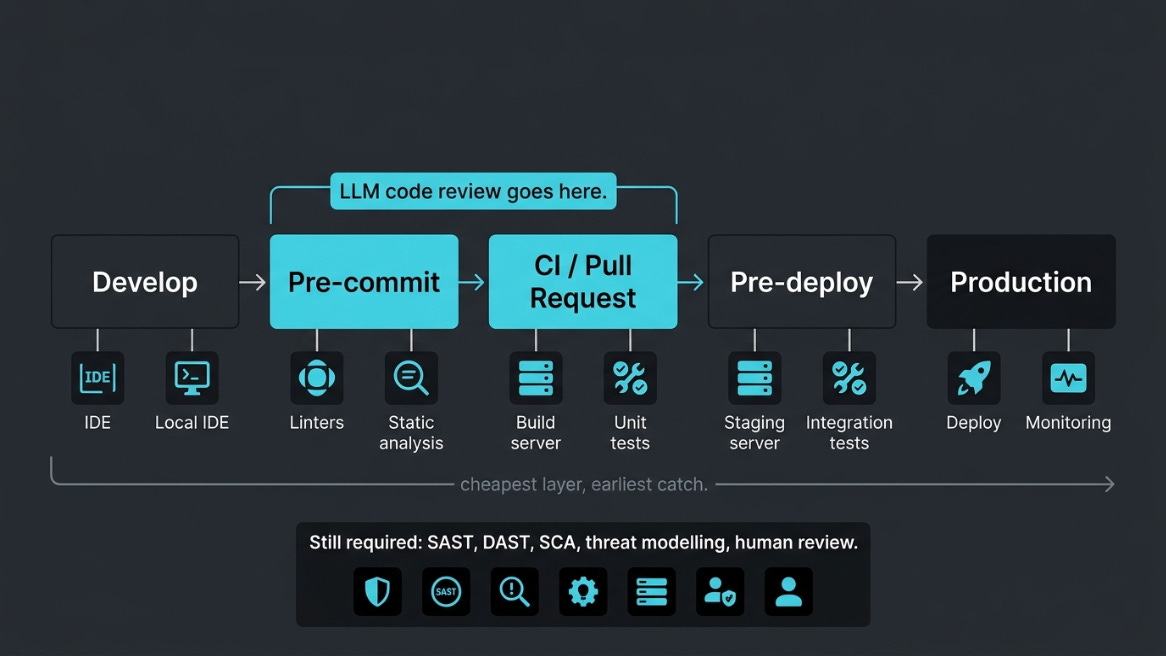
This is the cheapest layer in the secure-development lifecycle, and it goes in the cheapest seat:
Pre-commit hook for the developer’s laptop: fast feedback, no infra.
CI gate on pull requests: blocks the obvious before review.
It does not replace SAST, DAST, dependency scanning, threat modelling, or human review. It sits under them and removes their easiest catches so they can focus on the hard ones.
What it gets wrong
I ran the script on twelve real Flask repos from public GitHub. Of the findings it produced:
~80% were genuine, locatable, actionable bugs.
~15% were correct in spirit but wrong on line number or severity.
~5% were straight hallucinations - references to functions the file did not contain.
This is the working accuracy band.
Treat the output as a starting point, never as a verdict.
If the JSON says line 47 has a SQL injection and your file only has 32 lines, the model is wrong.
Do not silence it. Investigate.
Ethics
The reviewed file gets sent to a third-party API.
Do not run this on production code that contains real PHI, secrets, or proprietary IP you have not cleared for external processing.
For regulated codebases, point the same prompt at a self-hosted model: Llama, Mistral, Qwen all run this prompt acceptably on a single GPU. “The script does not log source to disk; the API provider’s data handling is on you to verify.
Do not run this script against repositories you do not own or have explicit permission to scan. Code review is not authorisation.
What’s next
The series continues with whatever turns out to be most useful to readers showing up here.
If you have a specific threat you are trying to brief your CISO on, reply to this post or message me and I will prioritize it:
Subscribe to get the next post the morning it drops. Free, no spam, unsubscribe with one click.
If you find any of this useful, the single most helpful thing you can do is forward it to one person on your security or clinical-AI team - that is how this series finds the people it is written for.
Views are my own and do not represent any employer, client, hospital, or institution I am affiliated with. This post is for security education and threat-modeling discussion only. Nothing here constitutes legal, medical, regulatory, or compliance advice - talk to your own counsel and your own clinical leadership before acting on any of it. The accompanying code is published for authorized defensive research only. Use it on systems you own or have explicit written permission to test.